5 reasons why machine learning has taken the lead in forecasting (with a caveat)
Lennert Smeets and Qixuan Hou - July 6, 2022

Machine learning (ML) has taken the lead in forecasting, there’s no longer any doubt about it and the series of Makridakis Competitions proves it. Until the M3-Competiton in 2000, it was all about statistical forecasting. The winner of the M4 edition in 2018 combined statistical forecasting with ML. And, in the M5 edition of 2020, all the top contributions were pure ML. The M5 results and analysis further confirmed that ML has passed the reality test with flying colors. It’s no longer just a promising technology, it’s the winning one.
How has ML achieved this remarkable breakthrough? Here are 5 reasons, with a caveat to put it in perspective.
1. Companies have more useful data
Blog post
The quantity of data becoming available to companies has increased enormously. This can be illustrated by the worldwide installed base of data storage capacity, which is growing at a rate of more than 15% every year. One factor is the ongoing digital transformation of businesses, which means that processes are increasingly monitored, producing lots of data that can be analyzed. Companies also have access to public or semi-public data repositories full of information useful for forecasting purposes, such as historical weather data, social media trends, and health statistics.
This huge increase in useful data is playing into the hands of ML, which requires a lot of data to work well.

Blog post
2. The continuing exponential growth in computing power
Blog post

The essence of Moore’s Law still holds. Gordon Moore formulated the law back in 1965, stating that the number of transistors on an integrated circuit would double every two years. Today, computers are still doubling their computing power every two years, and the cost of this power continues to go down.
All this incredible power is becoming available for ML forecasting, which is crucial because ML models require a lot more computing power than statistical forecasting. In some cases, it can take weeks to train an ML model. Therefore, any increase in computing power improves the business case for ML forecasting at the expense of statistical forecasting.
Blog post
3. ML models are becoming a lot more efficient
Developments in AI and ML are outpacing Moore’s Law, and by a distance. Stanford University’s 2019 AI Index report concluded that, since 2012, AI computational power has been doubling not every two years, but every 3.4 months. Stanford’s 2022 report signals a rapid decrease in training costs and a phenomenal increase in training speed for image classification systems, historically the most popular ML application.
A similar trend is now happening in ML-based forecasting. The algorithms are becoming more efficient in terms of required computational power due to research specifically targeted at the forecasting challenge. A prime example is LightGBM, which utilizes novel techniques allowing the algorithm to run faster while maintaining a high level of accuracy.
4. ML models have more expressive power
Blog post
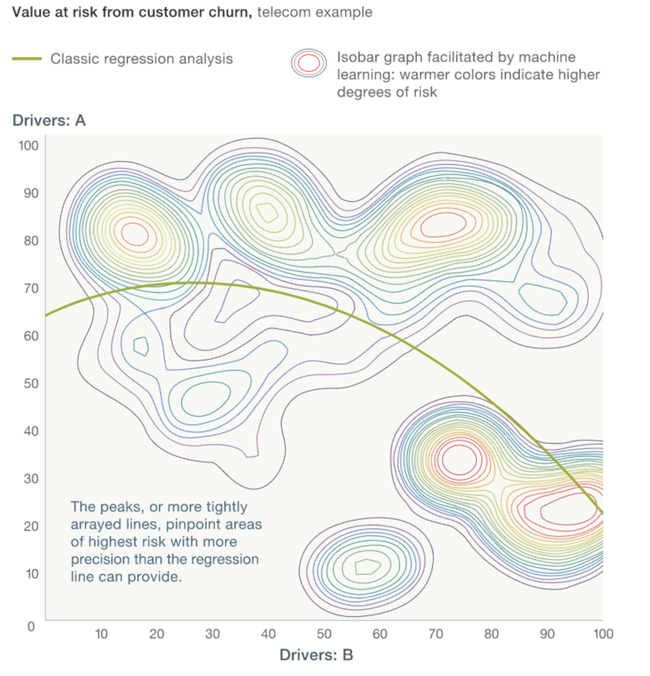
ML models can yield much richer results than classic statistical analyses such as linear regression. A striking example is the ‘value at risk from customer churn’ problem, a classic from the telecom business mentioned by McKinsey. For this problem, an ML model can provide insights along multiple dimensions, whereas the output of the regression analysis is a simple curve.
5. ML models are more flexible and versatile
ML models are more flexible and versatile than statistical analysis:
- A statistical model is always based on certain presumptions about the patterns that will be found in the data, such as the curve in the ‘value at risk from customer churn’ problem discussed above. ML, on the other hand, automatically figures out any pattern present in the data at hand, and continues to adjust the patterns as new data comes in.
- Statistical forecasting analyzes time series, one by one, independently of each other. ML, on the other hand, applies what we call cross-learning: while working a given time series, it remembers and applies the insights gathered from other time series, leading to superior results. A notable example in forecasting is the ability to cross-learn from the time series of different product families or groups.
Blog post
And the caveat?
Blog post

ML has definitely made it, and it’s expected to lead the forecasting challenge in the foreseeable future. However, all of the above doesn’t mean that ML is going to magically solve every forecasting problem. There are indeed a number of prerequisites:
- It only make sense to use ML if you have access to large amounts of relevant data.
- ML will not be a viable option if you don’t have the necessary computational power.
- Expert data scientists and a profound knowledge of the business at hand are needed to develop a suitable ML model, and select the right data to properly train it.
- You might encounter some internal opposition when deploying ML because it’s much more difficult to understand how the system works and the ‘criteria’ to be taken into account

Lennert Smeets
Senior Product Manager at OMP USA
Biography
Lennert oversees the R&D of OMP for Demand Management. He is mostly driven by looking for innovations that make our customer’s demand planning journey more manageable and, at the same time, more effective.

Qixuan Hou
Data Scientist
Biography
Primarily concentrating on demand forecasting, Qixuan works tirelessly to ensure customers get the most from the insights the OMP statistics engine uncovers. She particularly delights in conceiving and implementing action-oriented solutions to complex supply chain problems through collecting, cleansing, and analyzing data.