Machine learning is great, but is it going to crush statistical forecasting?
Lennert Smeets - May 3, 2021

Machine learning is the talk of the town but is it going to crush statistical forecasting completely? The recent success of machine learning in the M5 competition has inspired some commentators to predict the death of statistical forecasting, but I think they are cutting corners. While machine learning is rightfully claiming its place in demand forecasting, there are good reasons to believe that even many years from now it will be used in conjunction with statistical forecasting, as a complementary rather than substitute technique. Here’s why.
Statistical forecasting: extrapolating a well-defined set of data
Let me first briefly summarize the principles of statistical forecasting. The technology is all about using statistical techniques such as regression, sampling, and hypothesis testing on historical time series of sales data. The technique allows historical trends, seasonal patterns, and correlations with external factors to be identified. Trends are extrapolated, based on the assumption that past behavior is the best predictor of the future.
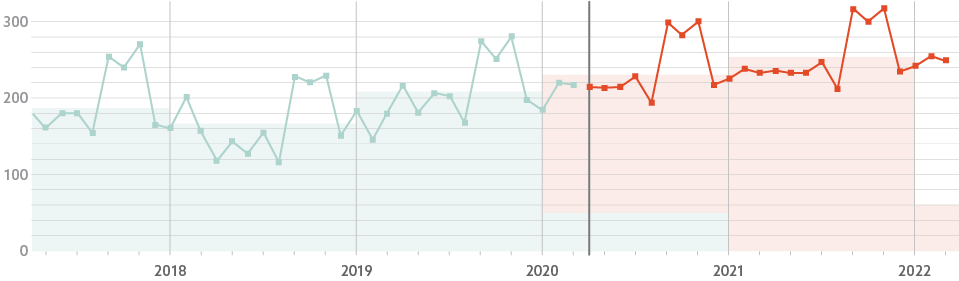
The frequently used Holt-Winters model, for example, essentially extrapolates the average values, trends, and cyclical behavior of the past to predict the future. The figure below illustrates what it does, showing the historical time series in blue and the extrapolated data in red.
Blog post
Blog post
Now, you don’t need a master’s degree in statistics to understand that the Covid-19 pandemic severely disturbed the time series in 2020 and into 2021, which undermines their predictive value. Demand forecasters now need to apply several additional techniques to smooth out or otherwise adjust the historical time series before using them to compute the forecast.
Does machine learning (ML) solve that problem? Not at all. Just like statistical forecasting, ML uses historical data, including the recent time series where its predictive value was undermined by the virus. The old GIGO principle (garbage in, garbage out) applies to ML as much as to statistical forecasting.
Machine learning: identifying patterns in a much broader range of data
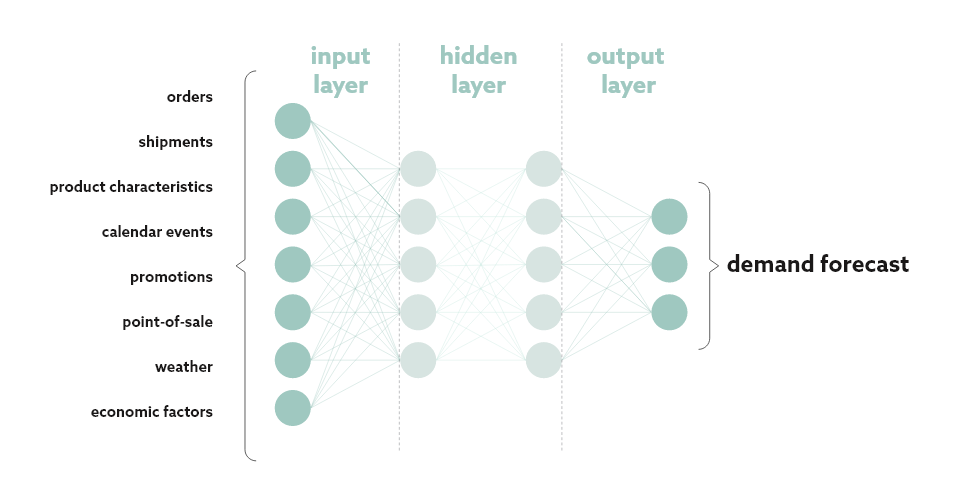
But ML does use these historical data in a completely different way, and that presents opportunities. Put simply, the neural network technique links inputs to outputs. There’s no need to define the model equation upfront. You just feed the machine with huge amounts of (carefully selected) input and output data, perhaps shipment data from a large number of products at different time intervals. Then, you let the machine identify patterns in the way the data are linked. This is the so-called learning phase during which the machine is trained and ‘wires’ its neural network
Blog post
Blog post
This immediately highlights one of the biggest appeals of ML: you can relatively easily feed it with a much broader range of data, with almost no modeling effort. You can add sales or shipment data from different products in the same product family, product master data, calendar data, promotional data, orders, point-of-sale data, the weather, and economic factors. ML identifies patterns somewhat ingenuously but if you’re feeding it with the right data you can make it smarter and smarter over time.
Machine learning has its downsides
Will this mean the end of statistical forecasting, as some have suggested after ML’s success in the M5 competition? Not so fast. The M5 competition used only one particular dataset, and we’re not so sure that the winning models would also work well on other datasets. There are also some downsides to ML, for example:
- ML models need a lot of data. If you don’t (yet) have a long history of data, or if you have a limited product portfolio, simpler statistical models are probably still your best bet.
- ML models have much heavier computational requirements. It can take several days to train a model, even on specialized hardware.
- ML models are inherently less transparent (more black box) than statistical models. While this is rarely a big problem, there might be some resistance in your organization to adopting ML because the models are less easily explained than statistical models.
- Most importantly, ML is not always guaranteed to lead to better forecast accuracy. The old adage in statistical modeling is still valid: simpler models are often better. In some cases, a simple moving average will provide better accuracy than a fancy ML model.
The techniques complement each other
Machine learning does have great potential but it does not guarantee the best forecast. Naive as they are, machines sometimes see patterns where there are none. And they are vulnerable to disrupted historical data in much the same way as statistical forecasting. I think it’s very likely that ML and statistical forecasting will be used as complementary techniques for many years to come. And neither can do without human intelligence, but that’s another story.
Do you want to know more about demand forecasting? Let me know how I can help!

Lennert Smeets
Senior Product Manager at OMP USA
Biography
Lennert oversees the R&D of OMP for Demand Management. He is mostly driven by looking for innovations that make our customer’s demand planning journey more manageable and, at the same time, more effective.





